
Judging the Cost of Replacing Cached Items - Dormando (June 3, 2026)
Introduction
Cache systems differ from databases: when full they must (quickly!) remove something to make room for new data. They do this by assigning a cost (or value) to items already in or new to the cache. Items are organized to quickly discover the lowest cost item to remove as new items enter.
Academic papers describe algorithms in terms of performance: achieving a high hit ratio (rate of cache hits vs misses), low latency, and so on. I want to reframe cache algorithm design as tradeoffs on costs. Memcached employs a principle of “least surprise” to assign cost. Hopefully by the end you will understand why!
In The Eye of the Beholder
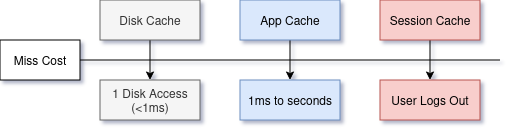
Deriving cost depends on where it comes from:
For a flash backed SSD filesystem cache, every miss has the same cost.
Items from applications vary widely: from cheap metadata to processed images.
Some are sensitive to tail latency, where cache items related to an active user must have fast access. Cost no longer just means “time to replace a missing item”
Some designs require fitting as much data as possible to save on hardware costs or fit a long tail of semi-active items. If most data is infrequently hit, you need a large cache to see benefits.
Some installations may be used as ephemeral key/value stores with nothing behind them at all! Rate limiting counters, session analytics, log rollups, etc. These rely on caches as being quick to forget while requiring a user can predict what gets forgotten.
For huge setups caches can end up organization shaped - prioritizing specific needs to an extreme.
You can see the difficulty in making a one-size-fits-all cache already.
Recency and Frequency
The value of a cache item decays over time. This gives the algorithm a sense of cost when replacing or losing data. Each one differs in its approach to finding the initial value and enacting the decay.
First In First Out and Least Recently Used as Building Blocks
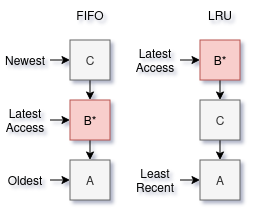
FIFO and LRU queues are the simplest ideas that most other algorithms are built on top of:
FIFO: Newest data is most valuable. Evicted items that are still useful will make their way back in from the top. For example users shop at a store for only a few minutes on average, or log data that is analyzed more when new.
LRU: Data which is used while already in the cache is highly valued. We make a bet that if it was recently used it will likely be accessed again. This looks like a FIFO queue except we move items back to the top when they are accessed.
The Many Faces of LRU
Random Sampling (known as K-LRU) will examine K random cache items (typically 5 to 16), and replace the least desirable one out of this list. These algorithms prioritize fitting more data in the cache at the expense of being less exact about which item to evict.
K-LRU allows a memory/time tradeoff if recently cached items are not strictly the highest value. A normal LRU requires items exist in a Linked List: every item needs to track previous and next items in the same list. When items are accessed they are removed from the list and then reinserted at the top. With random sampling we can avoid next/prev links by randomly probing the cache index (usually a hash table).
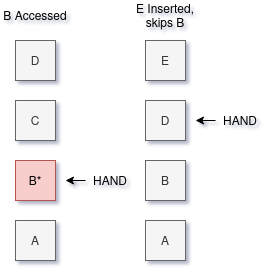
SIEVE is another interesting take: it sweeps through a list of items one at a time, moving only when new items are inserted. If this “hand” visits an item which has been accessed since it was examined by the hand, the item is left in place and the hand moves on. Value decays as items are inserted, rather than by item accesses or time passing. It also happens to be very simple.
 Note: Diagram is a simplification
Note: Diagram is a simplification
S3-FIFO is a mix-tape of FIFO and LRU: a split into multiple queues of different lengths. If newly inserted data is accessed within a short time, it gets moved into a larger FIFO queue. This values data which is inserted and immediately used. It belongs to a class of algorithms that protect against “scanning” workloads: like a web crawler that looks at every page on a site once. These systems ensure active usage, like a user browsing at a store, is not impacted by a web crawler examining every product in an inventory once.
S3-FIFO is also extremely similar to the memcached algorithm except it makes use of ghost entries, which we will discuss next.
Thou Shall Not Pass (sometimes)
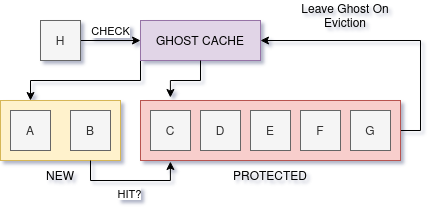
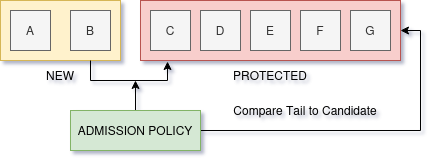 Note: Diagram is a simplification
Note: Diagram is a simplification
Another branch of algorithms focuses on the frequency of items being accessed, rather than purely if they were hit while in the cache. Systems like ARC, W-TinyLFU use methods of estimating how active items are even if they are not currently in the cache. ARC was patent encumbered (expired in 2024, finally!) which encouraged a lot of research in this area.
I will not be able to do justice to these algorithms while staying high level, so if these interest you please check out the papers or look for other writeups.
We have two approaches (S3-FIFO has some overlap here): the use of
ghost entries or statistical counters (which may act as ghost entries).
A ghost entry looks like a cache item, but without its data payload. This
allows the algorithm to guess if a newly inserted item had been in the cache
before: these entries have high cost because they continually re-enter
the cache. W-TinyLFU is similar
but can use less memory while also understanding how frequently an item was
accessed. When deciding to evict an item, it uses estimates to guess if a
new item is more frequently accessed than any old one.
Frequency estimates decay over time.
These systems work well when keeping relatively frequently accessed items in cache is most important. They struggle when there is an extremely long tail of infrequently accessed data: without enough ghost entries they cannot make educated decisions on what to keep in cache. More ghost entries take valuable space that could hold more of the tail.
What if… You Just Tell Us the Cost?
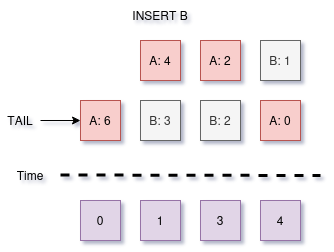
Sometimes I wish the memcached protocol (and internal data structures!) allowed users to just tell us how much they value a chunk of data. This is not a luxury we are allowed but it may not be much of a loss.
This is an entire class of algorithms, which trade some performance and memory efficiency in the hope of only removing items that are declared to be less valuable. An early paper on caching kicks this off. The idea was improved much later with GD-Wheel from 2015. Research continues, with for example CAMP - which estimates the cost per byte algorithmically instead of directly.
This sounds better than it works out in production scenarios. The algorithms can struggle to balance how many items in a cache are high cost vs low cost. Items enter the cache at their declared cost, then the value decays over time, so a high value item that has been cached will eventually be worth less than a low value item and be evicted.
Perhaps counterintuitively: low value items can become much higher value if very few of them are cached. Suppose during peak hours a glut of high value items are cached, pushing out low value items. This could overload a database that the low value caches were protecting.
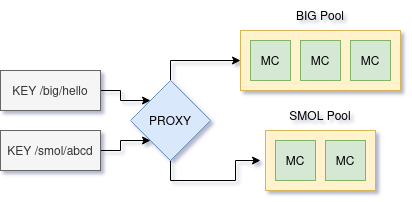
In production systems I have seen where there is a user defined cost of an item, multiple cache pools are used. Proxies or direct code are used to route keys to different pools. These cache pools are sized to guarantee they protect their backend system. Finally, splitting lets the user pick the most appropriate algorithm: high cost items use strict LRU, with low cost using an approximation to save memory and CPU.
Expiration Dates
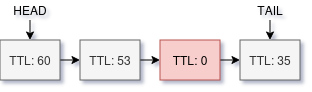
Another way a user can explicitly tell us the value of an item is by specifying an expiration time (TTL, or Time to Live). After this time they must not be returned to the user. To avoid filling a cache with holes we must actively remove expired entries as well. In the distant past memcached was completely passive, and caches could evict unexpired items so long as they were used less recently than an expired item.
At least one algorithm puts the highest value on fitting as much valid data as possible into the cache, with a bonus of being quick about it. On large enough installations this can translate into a lot of money. The downsides are tradeoffs: actively deleting items or overwriting items no longer reclaims memory immediately and the LRU is approximate. It may not be ideal if TTLs are not used at all.
The Cache of Least Surprise
Assumptions from these algorithms lead to surprises:
Putting data in cache, but it does not stay long. Even if it was not immediately used. (SIEVE, admission policies)
Deleting or overwriting data does not free memory. Sometimes the same item can be overwritten constantly!
Losing valuable cache data when crawlers flood a cache with low value items.
Losing random data when doing bulk data loads or overwriting data. Caches can be filled by periodic data loads! Data may only exist in the cache! (counters, etc)
Even algorithms where the user explicitly states the cost can lead to surprise. Memcached optimizes for what users and real workloads expect to see, while maintaining good hit ratios in more generic situations.
None of the designs we discussed are necessarily bad or wrong, but as consumers of this information we need to be mindful of selecting the right approach for our goals. Academic papers focus on (often old) cache traces supplied by social media or content delivery networks. Demonstrating a high hit ratio in these scenarios can miss pathological use cases that exist in the wild.
Conclusion
There are many ways of defining the cost of a cache item. Memcached takes the broad view of what this means, taking motivation from pieces of each of these approaches instead of taking any of them wholesale. We try to thread the needle: protecting from scans, avoiding performance pitfalls, and being memory efficient while supporting many features, without being perfect at anything.
Hopefully you now see how we got here, and learned some ideas for how caches can be applied to your system as well :)