
Caching beyond RAM: the case for NVMe - Dormando (June 12th, 2018)
Caching architectures at every layer of the stack embody an implicit tradeoff between performance and cost. These tradeoffs however are constantly shifting: new inflection points can emerge alongside advances in storage technology, changes in workload patterns, or fluctuations in hardware supply and demand.
In this post we explore the design ramifications of the increasing
cost of RAM on caching systems. While RAM has always been expensive, DRAM prices have risen by over 50% in 2017, and high densities of RAM involve multi-socket NUMA machines, bloating power and overall costs. Concurrently, alternative storage technologies such as Flash and Optane continue to improve. They have specialized hardware interfaces, consistent performance, high density, and relatively low costs. While there is increasing economic incentive to explore offloading caching from RAM onto NVMe or NVM devices, the implications for performance are still not widely understood.
We will explore these design implications in the context of Memcached, a distributed,
simple, cache-focused key/value store. For a quick overview, see the about page or the story tutorial.
- Memcached is a RAM backed key/value cache. It acts as a large distributed hash table, with data lifetime governed by an LRU. The oldest untouched data is evicted to make room for fresh data.
- Very low latency (sub-millisecond) and high throughput is important. Pages may request data from memcached several times, which can cause time to stack up quickly.
- Memcached is a huge cost reduction by cutting queries to your backend system. Either a database with flash/disk drives, or CPU-bound code such as templating or rendering.
Memcached has a storage system called extstore,
which allows keeping a portion of data for “less recently used” keys on
disk, freeing up RAM. See the link for a full breakdown of how it works,
but in short: keys stay in RAM, while values can be split off to disk.
Recent and frequently accessed keys will still have their values in RAM.
This test was done with the help of Accelerate with
Optane, which provided the hardware and guidance. Also thanks to
Netflix for their adoption of extstore, with all their great feedback.
Cache RAM Breakdown
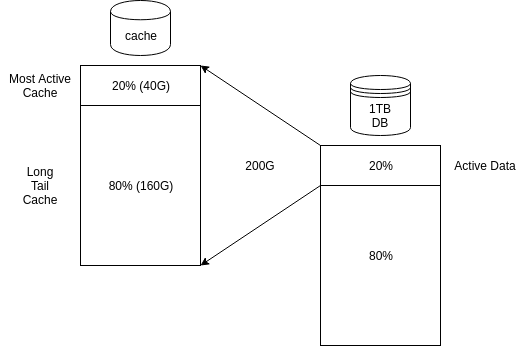
For example, a 1TB database could have only 20% of its data “active” over a given time period (say 4 hours). If you want to cache all of the active data, you might need 200G of RAM. Out of that 200G of RAM, only 20% of it might be highly utilized.
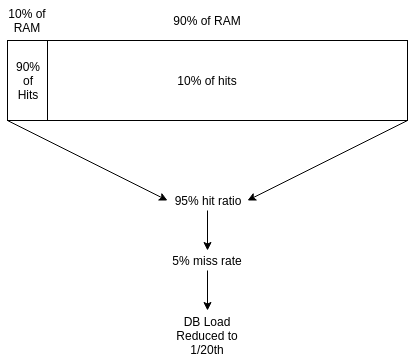
Of cache memory used, only 10% of the RAM could be responsible for 90% of all hits to the cache. The rest of the 90% of RAM only amounts for 10%.
However, if you cut 90% of the RAM usage, your miss rate would at least double, doubling the load on your DB. Depending on how your backend system performs, losing some RAM would double backend costs.

Breaking down items in memory, we might find that a vast majority (97.2% in the above case) live within only 30% of RAM. A smaller number of large, but still important items take up the other 70%. Even larger items can eat RAM very quickly.
Keep in mind these larger items can be a significant percentage of network utilization. One 8k request takes the same bandwidth as 80+ small ones.
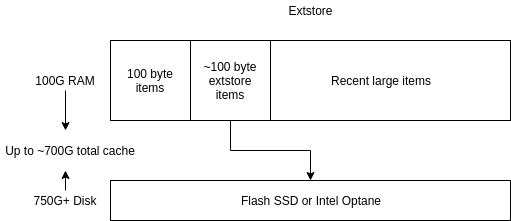
How does extstore help? By splitting the values from large less recently used items from their keys and pointing onto disk, we can save a majority of less-used RAM. Depending on use case, you can:
- Reduce overall RAM: cut 100G to 30G, or less, if you have a lot of larger items.
- Increase hit ratio with same RAM: move large items to disk, cache longer tail of small items, increase hit ratio and reduce backend costs.
- Reduce server count: if you have network to spare (and can handle the loss of broken servers!) you can cut the size of the cache fleet.
- Increase overall cache: easily add hundreds of gigabytes of cache capacity per server.
- Cache objects that used to be too expensive: create new pools with larger objects, caching precomputed data from big data stores, machine learning training data, and so on.
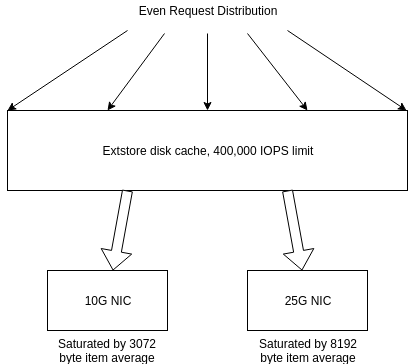
Are other workload variations okay? In the above example, cache hits are evenly distributed. This theoretical system has an IO limit of 400,000, which should be similar to a high end SSD or Optane drive. In this case RAM cannot be relied on to saturate the network.
At 400,000 IOPS, just 3072 byte averages are necessary to saturate a 10G NIC. 8192 for 25G. In properly designed clusters, extra headroom is necessary for growth, usage spikes, or failures within the pool. This means item sizes down to 1024 byte averages might be possible, however at 1024b (assuming 100 bytes of overhead per key), extstore will only be able to store 10x to disk of what it could fit in RAM.
Careful capacity planning is required:
- How many lost machines can be tolerated? Each dead machine takes a percentage of the cache with it.
- How much network bandwidth is necessary? Reducing the server count makes the network more dense.
- How many IOPS are necessary? Most accesses are against recent data, reducing the reliance on disk.
- What latency guarantees are necessary? If cache based disk lookups are still a lot faster than the backend
- How long do items live for? SSD’s only tolerate a certain amount of writes before burning out.
Test Setup
The tests were done on an Intel Xeon machine, sporting 32 cores, 192G of
RAM, a 4TB SSD, and 3x optane 750G drives. Only one optane drive was used
during the test. As of this writing extstore only works with one drive,
and this configuration reflects most of its users.
- mc-crusher was used to run the tests. Specifically, the third tag, containing the test-optane script.
- mc-crusher is designed primarily to run as fast as possible: it does not parse responses, stacks as many queries as it can per syscall, and makes no attempt to time anything. In this test it was run against localhost, though it never used more than a single core of CPU.
- The test-optane script specifically describes the configurations used in the test. Memcached was configured to use 32 worker threads (the machine has 64 cores with hyperthreads).
- The “balloon” program from mc-crusher was used to take up 125G of RAM, and 100 million keys loaded into memcached, to avoid extstore simply using the buffer pool.
Each test runs for a minute after warm-up.
Latency and Throughput measurements
Since mc-crusher does not time results, two scripts were used to generate the result data:
- bench-sample: Periodically runs the “stats” command against memcached, using its counters to determine average throughput. The data is sampled every few seconds, and was inspected for significant standard deviation.
- latency-sample: A script which pretends to be a blocking memcached client and “samples” requests over time, at the same time bench-sample is running. This is used to avoid traps like “95th percentile”, which removes outliers or grouping, causing misleading results.
Note: an event loop is not used, to avoid having to determine time elapsed as time waiting to be processed if a stack of events happen at the same time.
The Tests
Three general tests were done:
- ASCII multiget: this mode allows extstore to use the fewest packets to generate a response, as well as heavily pipeline requests internally. Lower latency devices can reach higher throughputs more easily with this test.
- Pipelined gets: many get requests are stacked into the same packet, but extstore has to service each request independently. In these tests, extstore was easily able to saturate the OS’s ability to serve buffered IO (kswapd kernel threads were maxed out), but the latency graphs show optane able to keep latency down 1/10th that of the flash drive.
- At higher client loads, pipelined gets may look odd: that will need further research, but is likely caused by queuing internally. Since mc-crusher is very aggressive, the optane drive is able to saturate the system with much fewer IO threads and crusher clients. In production workloads optane will provide much more consistent low latency service.
- Multiget + pipelined sets: the previous two workloads were read-only. In this test, sets are also done against memcached at a rate of roughly 1/3rd to 1/5th. Extstore is flushing to the drive at the same time as reads are happening. Again, optane comes out strong.
The Results
Unfortunately there is some wobbling in the graphs; that is due to
leaving too little RAM free during the tests. The optane’s performance
was consistent, while the OS struggled to keep up.
For reference: A pure RAM multiget load test against this exact
configuration of memcached (32 threads, etc) results in 18
million keys per second. More contrived benchmarks have gotten a
server with many cores up past 50 million keys per second.
With few extstore IO threads the Optane drive is able to
come much closer to saturating the IO limit: 4 threads, 4 clients: 230k
Optane, 40k SSD. The latency breakdown shows the SSD typically being an
order of magnitude higher in wait time, with the Optane staying in the
10us bucket, and SSD in 100us, slipping into 1ms.
With many extstore IO threads the underlying OS becomes
saturated, causing wobbles and queueing in the Optane graph. Meanwhile,
the SSD continues to benefit from extra thread resources, needed to
overcome the extra latency from flash.
For many workloads, both SSD and Optane are completely viable. If a bulk
of reads still come from RAM, with extstore used to service the long tail
of only large objects, they both keep requests under 1ms in response time.
If you want to push the boundaries of extstore a drive
like Optane goes a long way:
- High write tolerance goes well with cache workloads
- Very low latency helps smooth over the tradeoff of requesting cache data from disk
- Small size is currently adventageous: extstore requires RAM for every value on disk. 375G to 1TB of disk requires a lot less RAM in a particular machine, and 2TB+ is probably too dense to allow safe failover or avoid NIC saturation.
Learnings
- The extstore flusher is a background thread combined with the code which manages the LRU’s. During a benchmark, sets are consistently sent to the server, which can cause starvation of extstore’s flushing. In production, insert rates to memcached tend to come in waves, even as small as a millisecond across, so it can keep up. This will have more consistent performance as its own thread.
- Latency sampling is tough. The current script provides useful data, but a much better program would pace one request every millisecond onto a pool of blocking threads, allowing us to determine if the server is pausing or if some requests are simply slow. Full timing of every sample can also be saved and graphed. This would visualize clustering of responses which can come from the underlying OS or drive.
- Buffered I/O has limitations. This was known ahead of time, most workloads are in the order of hundreds of thousands of operations per second or much less, and most of those will be against RAM and not extstore. We’ve focused on stability for the time being, but eventually direct IO and async IO will be able to better utilize the devices under high load.
- Extstore’s bucketing could allow for a very interesting mix of Optane along with traditional flash. Internally, extstore organizes data into “pages” of disk space (typically 64M). New items are clustered into particular pages. Items with short TTL’s can be clustered together. Items which survive page compaction are clustered as well, which reduces the need for compaction over time. All new items and/or short TTL items could rest on a 375G optane drive, while compacted items could sit on a 1TB flash drive, providing even greater cost savings.
Conclusions
Workloads which aren’t currently possible due to cost are now possible.
Most workloads containing mixed data sizes and large pools can have
significant cost reduction.
Extstore requires RAM per item on disk. This chart, assuming 100 bytes of overhead per item (key + metadata), visualizes how the RAM overhead falls as item sizes get larger.
DRAM costs are 3-4x Optane, and 4-8x SSD, depending on the drive.
As cache shifts from RAM to Optane (or flash), money spent purely on RAM can drop to 1/3rd.
Reducing RAM reduces reliance on multi-socket servers to get very high RAM density, NUMA capable machines are often necessary. These have multiple sockets, multiple CPUs, with half of the RAM attached to each CPU. Since memcached is highly efficient, you can both cut RAM, as well as cut half of the motherboard/CPU and even power costs once RAM is reduced. Cost reductions up to 80% for specific workloads are reasonable.
High speed, low latency SSD opens a new era for database and cache design. We demonstrate high performance numbers for a wide variety of use cases, for both reduction of costs and expansion of cache usage.