
The Volatile Benefit of Persistent Memory: Part Two - Dormando (May 8, 2019)
Given this entirely new (to us) hardware platform, we hoped to find new directions to explore. What we found was fascinating: the problem is a lot more boring than anticipated.
Future: Observations from Experiments
We did a small survey of datastructures: DRAM and PMEM are very similar, but PMEM has more latency. Memcached has a traditional chained hash table. Are there any more modern datastructures that would reduce the number of round trips to PMEM enough to make a difference?
We haven’t (yet!) found anything that would make a huge improvement. The rest of this post will walk through a few of these ideas and what came of them.
It turns out our existing data structure is well optimized in the face of PMEM. The LRU algorithm tries to minimize mutations to the LRU on frequently accessed items. From there, most memory accesses happen in item metadata, which fits in DRAM cachelines (64b). PMEM’s own cachelines are 256 bytes, which will often encompass the metadata and the entire key. This means comparing the key to find a match, and the resultant metadata checks, result in a single fetch to the underlying PMEM.
Frequently accessed items benefit from processor cache as well, so hot or very recent keys get a performance boost without doing any further work.
Chained Hash Table
Theory: chained hash tables have poor performance when buckets are deep, which may be compounded by PMEM’s latency.
Reality: memcached autoresizes the hash table before it passes an average depth of 1.5 items per bucket. There is only a small performance difference.
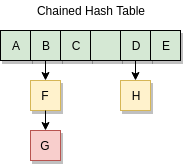
A primary concern was the chained hash table. The hash table is implemented via a flat array of pointers. A key is hashed into a bucket number, and if the bucket is non-NULL an item is found. Then the key must be compared with the request to ensure it was the exact item requested.
In the case of a collision, the bucket “grows” deeper via a singly linked list. A pointer within the item structure points to the next hashtable item. This means each item found that is not the desired item will create an extra roundtrip to PMEM.
Memcached automatically doubles the size of its hash table after the number of entries (the “load”) is 150% of the size of the original array. Hash table density will then vary between a load of 50% and 150%. If the hash algorithm is completely fair, the average bucket depth will be 1.5 worst case. In reality the worst case will be higher than 1.5, but not much more.
For a quick test, we filled memcached with 201,326,591 items, enough to sit just under 150% hash table load. We then forced the hash table to expand, dropping its load to 50%. With this setup we ran our “realistic-ish” paced load test from before, which uses a large number of client connections.
Here we look at the average latencies of a syscall-heavy test, only varying the size of the hash table. All requests are being served from persistent memory. The latencies drop slightly as the server gets busier and clocks stabilize, then start to rise as it gets overloaded. The p99 latency for these tests were random, due to the nature of the test being lots of queued connections and the performance being close together. Only the actual average showed a consistent difference over multiple test runs.
We see the the oversized hash table did win. Notice how close the latencies are: the worst-case hashtable tends to lose by 5 microseconds on average. If you need to wring every last drop of performance, oversizing the hash table can help. Otherwise, it isn’t a huge win.
Refcount Burn
Theory: every read causes writes to persistent memory: refcount updates, LRU mutations, etc. Could lead to a big problem.
Reality: almost no difference. Disabling refcounting and LRU shuffling was benchmarked, showing only a 5% improvement.
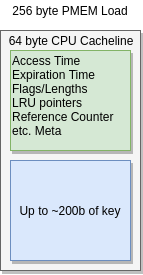
Most memory accesses are outside of item memory: connection buffers, statistical counters, even the hash calculation is performed on the request input buffer rather than item memory in most cases.
To satisfy a GET request, item memory is barely touched:
- The item key is compared to the request buffer in order to complete the hash table lookup.
- Expiration time is tested.
- The reference counter is increased if it matches.
- Some bit flags and “last accessed time” may be updated, if they haven’t been recently.
- The key+value are asynchronously written to the client socket.
- Reference counter is decreased.
Since Intel PMEM loads memory in 256 byte slices, small enough items may incur just a single read for most of the work. The rest of the small reads are handled by CPU cache. The LRU, last access times, and flags aren’t always updated on a read. For busy items only the two byte refcount would be adjusted. Even though the item metadata is referenced a few times in code, the latency penalty from accessing PMEM is fixed.
Tiered Memory
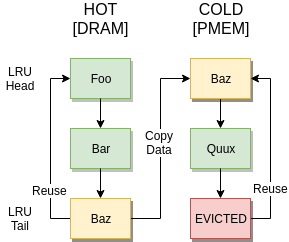
Theory: Recently inserted items are most likely to be either accessed of replaced. Flushing items to PMEM when they’re less used should improve performance.
Reality: It’s slower
The LRU algorithm conveniently splits memory into HOT (new), WARM (frequently accessed), and COLD (less frequently accessed). What if COLD items were on PMEM and HOT/WARM stayed in DRAM?
On a full cache, each new SET would cause:
- Tail of HOT must transition to COLD, copy to PMEM.
- To do this: tail of COLD must be evicted to make room for the item from HOT.
- Finally, HOT gets its item data.
This makes sets twice take twice as long, and improvements to read performance aren’t high enough to offset this. Items which are very frequently hit will sit in the processor cache, making PMEM performance irrelevant.
Buffer Cache
Theory: frequently accessed items use a RAM buffer cache.
Reality: Possibly actually better, but a large change.
In contrast with the tiering approach, SET’s from new items would be unchanged. When an item is accessed, it can probabilistically be pulled into a buffer cache in DRAM. Further reads would hit the cached item. Making use of random chance would reduce overhead of evicting memory from the buffer pool for infrequently accessed items.
The original item would stay in place in PMEM, and a fake item linked into the hash table. The fake item would point back to the real item; on DELETE or OVERWRITE or dropping from buffer pool, the original memory is restored or freed.
Requires significant code changes to accomplish, and the read performance improvements would be small; likely only useful for extremely sensitive applications. Keys which become very hot would be the same performance as without a buffer cache, again on account of CPU caches.
Adaptive Radix Trees
Theory: ART’s could be used in DRAM to avoid checking PMEM to compare keys during lookup, without using tons of memory.
Reality: Could work, but tough to scale and chained tables perform well currently.
Adaptive Radix Trees are a very interesting relatively new data structure. With ART’s, you don’t need to hash a key in order to look it up. It’s also not necessary to compare the full key to the final node before deciding if a match is good. Memcached’s existing chained hash table might have to fetch into PMEM multiple times just to locate an item; an ART may stay entirely in DRAM, only fetching the item data on a successful match. Further, it may even make sense to run the ART directly in PMEM due to its sorted nature.
An Inefficient Memcached Key
departmentname:appname:subsystem:userdata:picnum:{id}
ART Prefix Compression
[departmentname:][appname:][subsystem:][userdata:][picnum:]{id}
Unfortunately ART’s lose in the details: memcached can store hundreds of millions of keys with similar prefixes, but vary by a number of digits at the end. This can lead to multiple hops around DRAM before locating an entry. Further, research into concurrency of such structures is sparse. Existing methods require locking at each stage of the lookup. Concurrent writes can cause full restarts of a lookup. By comparison memcached’s chained hash table requires a single mutex lock to make a lookup, and the hash calculation we were happy to avoid is done before any locks are even acquired.
There may be potential in the future; we’re keeping an eye on this space.
External reference counters
Theory: Looking up items requires writing to the refcount twice. Moving this to DRAM could save on perf. and device longevity.
Reality: Indirection is slow, 5% performance benefit at most. Possibly worth experimenting with.
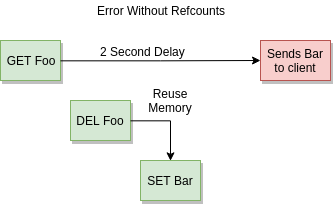
Since many items can be requested at the same time, hazard pointers and similar constructs would scale poorly for memcached. For the time being we are stuck with reference counting. Contrary to the ideas of some academic papers; the reference counters are not for locking or concurrency, but safety and correctness. Keys and values are copied to a client via scatter-gather networking. If a client is slow to read data, a long time can pass before an item’s memory is sent to a client. Without copy-on-write and reference counting, an item’s memory could be “deleted” and then re-used. The wrong data would then be sent to a client. A catastrophic bug.
One idea is if the keys and values of items are small enough there is a size cutoff point where simply copying the value into a buffer while the item is locked is faster than bumping the refcount twice. This is especially true as right now a full mutex lock is required to decrement the reference counter, though this may be fixed in the future.
Items do not carry their own mutexes: a separate smaller table of mutexes is checked and items
with similar hash bits share mutexes. This table could be extended with an
array of [POINTER,refcount] for each lock, expanded or contracted as
necessary. If an item has no references, it would have no refcount memory.
This could save two bytes per item.
This is a complex change, and the maximal impact is less than 5% performance and two bytes of memory. With an external reference counter we may be making more accesses to DRAM as well. In the end, an external reference counter in DRAM could be slower than accessing it inline to item metadata via PMEM.
Conclusions
The existing memcached works very well with Intel® Optane™ DC Persistent Memory Modules. Improving performance will be challenging. Enough so that it might not be worth doing. This allows us to focus on features and stability without having to invest a lot of time in making the service “PMEM compatible”.
Still, we are early in the life of modern persistent memory. Currently our hashtable sits in RAM, but perhaps this could move into PMEM as well. Are there scenarios where even client connection buffers could simply use PMEM?
What other features have we been skipping or missing all this time just to save memory?