
The Volatile Benefit of Persistent Memory - Dormando (April 30, 2019)
- How can persistent memory be used today, with memcached?
- How will persistent memory be used in the future?
In collaboration with Intel, we experimented with Intel® Optane™ DC Persistent Memory Modules (hereby referred to as PMEM) and a minimally modified memcached to answer these questions. This post looks over benchmark results and possibilities for future code architectures for cache systems.
Persistent Memory
Intel® Optane™ DC Persistent Memory Modules are DDR4-compatible memory modules that can remember memory after powering off, without the aid of batteries. It does require compatible motherboards and processors to operate, however.
DDR RAM come in flavors of speed, features, and density. For servers, features and speed tend to be decided by the pairing with other components in the system: motherboard, CPU speed, and so on. The primary choice to make is how dense you want RAM to be.
Typical DRAM modules for servers are (as of today) between 8 and 64 gigabytes in size. Each density has its own price range:
DRAM
16G $7.5/gigabyte
32G $7/gigabyte
64G $9/gigabyte
128G $35/gigabyte
128G modules are new and rare, with extremely high costs to match. System builders must decide on tradeoffs: memory slots vs DRAM density. Cloud providers typically want dense, small, inexpensive systems.
These new modules from Intel come in densities of 128G, 256G, and 512G. The cost-per-gigabyte is lowest at 128G and highest at 512G. System performance scales with the number of modules in the system.
For cache systems, the 128G modules seem to fit the sweet spot. The rest of this post explores the performance of a system configured with 128G modules.
Benchmarks
With minimal changes, or none at all, what performance charactistics do we see? What can we learn about how to design the future? We went with three main configurations:
- No code changes. Just DRAM baseline on the supplied hardware.
- No code changes, using Memory Mode to expand system memory.
- Minimal code changes: only item memory on persistent memory storage.
Why not extstore?
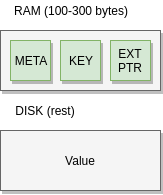
Extstore is an extension to memcached which utilizes standard SSD/NVME devices to offload memory. It achieves this by keeping metadata and key data in RAM, and pointing the “value” part of an item onto storage. This tradeoff works well for items with relatively large values (1k-8k+). At low sizes (sub 1k), you need an high amount of RAM relative to the disk space you can use.
While extstore works well for large values, memcached lacks a story for handling a large volume of smaller items. PMEM could also be combined with Extstore: item metadata and keys in PMEM and values on NVME flash storage.
Test setup
Tests were done using memcached 1.5.12 and mc-crusher - the test scripts are available here
The tests were run on a single machine running fedora 27 with a kernel build of 4.15.6. The machine hardware specifications were:
- 2x Xeon Cascade Lake CPUs (24 cores, 48 hyperthreads each)
- 12 x 16GB (192GB) of DDR4 RAM
- 1.5TB of Intel Optane DC Persistent Memory in a 2:2:2 config
- 1 SSD for OS disk
The test machine was a NUMA multi socket server. One NUMA node was used to run the memcached server. The other was used to run the mc-crusher benchmark. A CPU core was also reserved for a latency sampling process.
The following OS level configuration changes were made:
/usr/bin/echo 1 > /sys/devices/system/cpu/intel_pstate/no_turbo
echo "4096" > /proc/sys/net/core/somaxconn
cpupower set -b 0
cpupower frequency-set -g performance
- Turbo was disabled for consistency. The tests are ramped by number of CPU cores dedicated to mc-crusher, which would end up being faster for the first few cores if turbo were enabled. It could also cause different results run to run.
- No minimum frequency was specified, but the performance CPU governor was enabled.
- somaxconns raised. “paced” tests use a large number of connections which are quickly established. This avoids dropped connections.
- load generation was done over UNIX domain sockets. TCP over localhost while crossing NUMA nodes had severe performance limitations and oscillating results.
the latency sampler application used TCP over localhost, as alone it did not suffer the same regression as the main benchmark. This is to get latency results closer to reality by adding the TCP stack back in.
For all tests, item value sizes are 256 bytes. Together with key and metadata items were slightly above 300 bytes on average.
The number of keys loaded into the server for the tests are 125 million or 1 billion. This provides a baseline of performance, then shows the added overhead when expanding beyond DRAM’s limits. In both cases the hash table has a 93% load factor, which is discussed below.
Patches to Memcached
Three small patches were used to assist in the benchmark.
Patch to allow listening on UNIX domain sockets and TCP sockets at the same time. This is usually disallowed since users can easily misconfigure a client or accidentally leave a localhost-locked instance on the internet. With this, we can sample latency via the TCP stack while generating load via UNIX sockets.
Patch adding a command to force the hash table to expand. Normally memcached auto-expands its hash table after the hash table usage has hit a 1.5x item-to-buckets ratio. For some experiments we tested oversizing the hash table. Details below.
Patch malloc’ing memory when items are created with a specific client flag. This was not used in benchmarking, but used in experiments.
The Tests
Memcached Configuration
In all cases memcached is configured to use 48 worker threads. The same startup arguments were used for all tests, only varying how much memory is used, and where it came from. The only other change is disabling the LRU crawler. This is a low priority background thread and we ensure it isn’t interfering with test results at random.
Connections to memcached are sticky to a specific worker thread. All of the tests below create at least enough connections per benchmark thread to utilize all of memcached’s worker threads.
Hardware Configurations
This quickstart guide is similar to how we configured the hardware for each test.
The different modes of the Optane memory are described here - we use Memory Mode and App Direct.
DRAM
- These tests are DRAM-only, persistent memory is not used. This is the baseline performance.
Memory Mode

- For these tests Memory Mode is enabled. This mode stitches the system DRAM with persistent memory to look like one big pool of volatile memory. There is no persistence of data. All is lost on reboot.
App Direct Mode
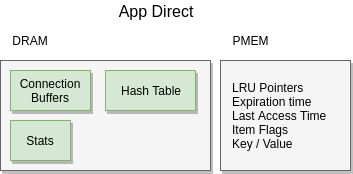
In this mode DRAM is used for memcached’s internal structures and buffers, as well as the main array of its chained hash table.
All item data: metadata, key, and value are stored directly in a persistent memory region.
Persistent memory is enabled using a DAX filesystem and a prototype patch for memcached’s restartable mode. The persistent memory is accessed via a mmap’ed file.
NOTE: restartable mode has been released in 1.5.18. Simply add
-e /path/to/dax/mount/memory_fileto have memcached utilize app direct mode.NOTE: It’s possible to make use of hugepages to improve performance of the DAX filesystem. We did not test this, but it could provide a significant boost in some situations.
Results
Random selector:
uniform - select keys at random, every key has same chance of being fetched.
zipf - select keys on a power curve, lower numbered keys fetched more
frequently.
Key count:
1 billion - 300G+ of storage. NOTE: DRAM baseline is always 125m keys.
125 million - working set fits in RAM for all hardware configurations.
Throughput tests: 48 connections per bench. core. Maximum request rate.
Heavily batched requests and responses. Low syscall rate.
Heavily batched requests, non batched responses. Medium
syscall rate.
Latency tests: 50 requests every 75ms per connection. 400 connections per
bench core. High syscall rate.
Read-only
99% read, 1% write
90% read, 10% write
Latency Percentile: - only affects Latency test graphs
Tuning these tests were a real challenge. In most of our experiments all three modes worked nearly the same. The fact that differences are visible here was an exercise in creativity.
DRAM acts as our baseline, but since we don’t have 400 gigabytes of RAM there was no easy way to compare DRAM directly vs PMEM for large workloads. This comparison is still valid: what we present is a comparison of having many machines with a DRAM-fitting workload vs one machine with a much larger than DRAM workload. Below are some quick interpretations to help understand the test results:
- DRAM is as-expected.
- Memory Mode is in the middle. Close to DRAM up into around 8 to 10
million requests per second in all tests.
- Under “latency” workloads Memory Mode starts to differentiate. When many sets are mixed in it degrades above DRAM and PMEM mode, but not enough to violate a 1 millisecond deadline until nearly 8 million requests per second.
App Direct mode is a real surprise: without caching any memory at all, unlike Memory Mode, performance is both better and worse.
- When the workloads fit in DRAM (125 million keys), App Direct mode is very close on latency but loses slightly to both DRAM and Memory Mode.
- With the 1 billion item workload, App Direct almost consistently beats Memory Mode. Total throughput can be lower at a still ridiculous 20+ million requests per second, but latency is comparable. the PMEM does very well in the paced tests, including the mixed read/write scenarios.
The zipf distributions improve both Memory Mode and App Direct, with significant gains in throughput and latency. Memory Mode tracks DRAM throughput much more closely.
Average latencies are nearly identical under paced tests. Memcached touches item memory very little while processing a request, so while App Direct has higher latency, the difference is drowned out by everything else going on.
We spent a long time validating, re-running, and re-optimizing these tests. If you’re used to testing normal SSD’s, or even NVME drives, these results are unreal. Lets next discuss how this relates to a production deployment.
What works today?
Users of memcached have two bottlenecks to plan around: the network, and memory capacity. More recently, extstore users have to contend with flash drive burnout for workloads under heavy writes.
Network throughput
Throughput is nearly unlimited. In all cases a real network card would fail before the service would. 10 million 300 byte responses is over 20 gigabits of traffic. In almost all known memcached workloads, items vary in size significantly, from a couple bytes to half a megabyte or more. A system could easily saturate a 50 gigabit network card if it has a variety of item sizes stored.
Lets take 300b, 1kb, and 2kb TCP responses (key/value + TCP/Frame header). Now, assuming an 8 million requests per second ceiling for a heavy somewhat realistic read load for the machine we tested, what does NIC saturation look like:
At an average value of 2 kilobytes it becomes plausible to saturate a 100 gigabyte NIC with a single instance. Reality always pulls these numbers lower: syscall overhead, interrupt polling rates, and so on. Memcached also presently doesn’t scale as well on writes. We will have to put in effort to hit 100 gigabits for high write rate workloads.
People often reach for DPDK or similar custom userspace networking stacks on top of specialized hardware. Memcached prefers to keep deployment as simple as possible and does not support these libraries. Further, very few users ever break 100k requests per second on a single node, so they aren’t typically needed.
From what we see, PMEM is equivalent to DRAM for typical network cards.
Memory Density
Memory density is the other major factor determining how many memcached servers a company needs. You need enough RAM to get a high hit ratio to significantly lower backend load, or to fit a working set in memory.
There are limits to how few memcached instances you can have. During a failure other servers must pick up the slack: both database backends taking on extra misses and the network cards of remaining memcached nodes.
Having a new level of density gives more opportunity to expand the size of data caches as well. Cache more data from foreign datacenters, of AI/ML models, of pre-calculated or pre-templated renderings.
We’re off to a strong start. Even without modifying the existing code, the service performs nearly identically to DRAM in any realistic scenario. If we want to improve this situation, a user would need to first be extremely sensitive to microseconds of latency. The only other goal to optimize for is device longevity by reducing writes to PMEM. Intel guarantees full write loads for 3 years, but this could matter if a company intends to use the hardware for 5+ years under heavy sustained load. Still, if flash devices are out of reach due to concerns about early drive burnout, PMEM is a good alternative.
On that note, if you match any of these conditions we would love to hear from you! We aren’t aware of any user who would be limited by this.
Restartable Cache
A feature released in 1.5.18 allows memcached to be restarted if cleanly shut down. For a lot of workloads this is a bad idea:
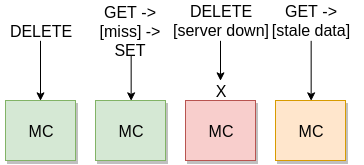
However, if your application has the ability to queue and retry cache updates or invalidations, or it simply doesn’t matter for your workload, restartability can be a huge benefit. Memcached pools are sized as N+1(ish). You need enough servers to tolerate the extra miss rate when one goes down. If a server is upgraded, you have to wait for the replacement server to refill for a while before moving on.
With restartable mode the item memory and some metadata are stored in a shared memory segment. When memcached restarts, if it’s still compatible with the old data, it will rebuild its hash table and serve its previous data. This allows upgrades to be more easily done. This functions the same whether you are on DRAM or PMEM.
Even with this, you still lose the cache when rebooting a machine, such as with a kernel update. With Persistent Memory in App Direct mode, you can completely reboot (or even repair) a machine without losing the cache, since that shared memory segment will persist across reboots. So long as it’s done in a reasonable amount of time!
This change doesn’t make memcached crash safe. It is designed under a different set of tradeoffs than a traditional database.
TCO
Maximizing network usage, increasing memory density, and reducing cluster size can reduce TCO by up to 80%. Lets break this down.
Hardware Cost Metrics
- Cluster size: Network Ports, Power Draw
High end switching (10g, 25g, 50g) can cost hundreds to thousands of dollars per network port. Reducing the number of cache servers reduces port usage and electricity costs. Since memcached can make good usage of larger network cards, assigned capacity won’t go to waste.
- Single vs Dual Socket servers
Memcached workloads require little CPU. Users may be running dual-socket systems just to get more RAM into a single system. Switching from a dual socket to single socket system alone can cut per-server costs nearly in half.
- RAM Density
DRAM prices always have a curve, for example (for current server DIMMs):
- 16G modules at $7.5/gigabyte
- 32G modules at $7.0/gigabyte
- 64G modules at $9.0/gigabyte
Per-gigabyte costs for PMEM are (as of this writing) roughly half of DRAM of similar densities.
(Note: RAM pricing fluctuates, these numbers are for illustration purposes).
256G 32G 256G
DRAM DRAM Optane
+---+ +---+ +----+
|32G| |16G| |128G|
| | | | | |
|32G| |16G| |128G|
| | +---+ +----+
|32G|
| | $7.5/gig $4.5/gig
|32G|
| | $1392 total
|32G|
| |
|32G|
| |
|32G|
| |
|32G|
+---+
$7/gig -> $1792 total
Take the two examples above: to have 256G of cache one configuration could require 8 RAM slots, at $8 per gigabyte. $2k for RAM. Getting 8 slots could also require multi-socket servers, more expensive motherboards, or higher density RAM in fewer slots at a higher price. A combination with PMEM still requires some RAM, but in total you can cut thousands of dollars off the cost of a single cache node.
Hardware Cost Scaling
The above example shows nodes with 256G of DRAM. Performance scales nearly linearly as modules are added to a machine. Multi-terabyte nodes could be used to drastically reduce size of a cache cluster, network permitting.
Dramatically increasing cache size could reduce costs elsewhere: internet bandwidth or cross-datacenter bandwidth, expensive database servers, expensive compute nodes, and so on.
The Question Of Cloud Pricing
Direct hardware purchases are easy to calculate if you run your own datacenters. How does PMEM fit in with the cloud pricing most people are paying these days?
Cloud pricing is a big wildcard for this new technology right now. When NVME devices were introduced recently, cloud providers were putting 4TB+ drives in large instances with a maximum amount of storage and RAM. These instances were very costly and were not a great match for memcached or memcached with Extstore.
More recently nodes have been appearing with smaller amounts of NVME (750G to 1TB or so), with reduced CPU and RAM to go with. We would like to see cloud providers offer customers instances which fit into this market:
- Lower amounts of RAM (16 to 64G)
- Lower CPU (4-12 cores)
- A scalable amount of PMEM (256G to terabytes)
- Scalable network performance
The cache and key/value storage layers are an important part of most infrastructures. Having instances tightly coupled to the needs of cloud users can be make or break for startups, and a huge line item for established companies. Users are able to push to market faster if they don’t have to worry as much about sections of their architecture which may be difficult or costly to scale.
Conclusions and Part Two
Intel® Optane™ DC Persistent Memory Modules have a high density, and very low latency. Compared to the needs of a database, memcached makes extremely few references to PMEM, so performance is nearly the same as DRAM: easily beating 1ms (even 0.5ms) SLA’s at millions of requests per second. PMEM can also drive large cost savings by either reducing cluster size or increasing available cache. Further, with Memory Mode deployment is trivial for old versions of memcached.
With NVME and now PMEM, we see new classes of ultra high density cache clusters:
- Reduce inter-DC traffic (web objects, image data, content delivery networks)
- Reduce backend load.
- Cache ML inference data.
- Look-aside blob cache for streaming services.
- Any pain point or cost center with temporary data storage.
As with the NVME rollout last year, we see this as an exciting time for datacenter storage. Revolutions come along rarely in this industry, and we welcome everything we can get.
We continue this discussion in part two, with a look into software and algorithmic changes we thought through and tested during the course of this project.